
Elvis Cruz Chullo

Que son los Transformers
Los Transformers son un tipo de modelo de inteligencia artificial diseñado para procesar y entender secuencias de datos, como el lenguaje o el texto. Fueron creados para ayudar a las máquinas a comprender mejor las relaciones entre palabras en una oración o incluso en textos largos.
Son la tecnologia que esta transformando el mundo
Antes de continuar , si esta interesado en leer previamente el paper y entenderlo por tu cuenta te dejo el link:
Attention Is All You NeedLa primera vez que leí el paper de Google, Attention Is All You Need, me pareció muy complicado. Te traigo una explicación sencilla para entenderlo
El Transformer es el primer modelo de transducción que se basa completamente en la auto-atención para calcular representaciones de su entrada y salida, sin utilizar RNN alineados en secuencia o convoluciones.
La idea clave del Transformer es gestionar completamente las dependencias entre la entrada y la salida con atención y recurrencia.
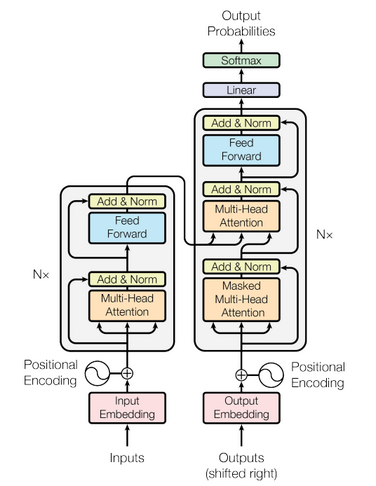
Revisando la arquitectura de un Transformer
El Transformer utiliza un Encoder y un Decoder como sus componentes principales.
El Encoder se encarga de procesar el contexto de la secuencia de entrada, mientras que el Decoder genera la secuencia de salida a partir de ese contexto.
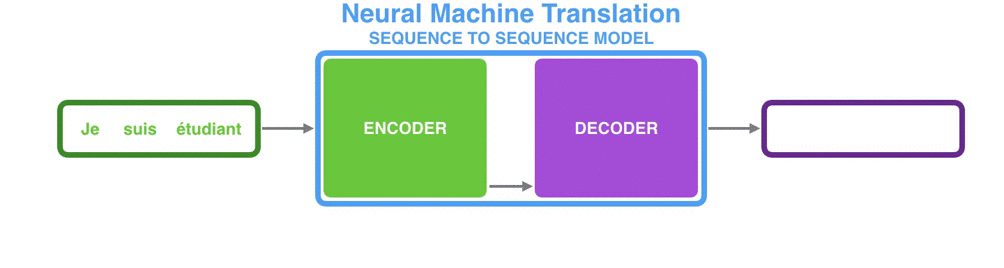
En la animación de abajo, puedes observar cómo funciona este proceso en una tarea de traducción de texto
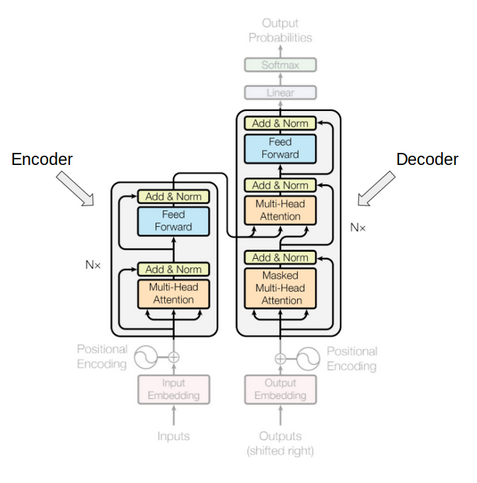
En la figura del paper Attention Is All You Need se ve claramente esa diferencia entre esos 2 bloques
Embedding del texto
En NLP, el Embedding se refiere a convertir las palabras en vectores. Lo interesante de esta transformación es que obtenemos una representación numérica de las palabras, donde aquellas con significados semánticamente similares se encuentran próximas entre sí en el espacio vectorial.
La Posicion de las palabras
La posición de una palabra es crucial para que el modelo pueda interpretar correctamente la secuencia que se le proporciona.
En las RNN, la arquitectura recurrente asegura que el orden de las palabras sea importante. Sin embargo, el Transformer abandona este mecanismo recurrente en favor del mecanismo de atención múltiple, lo que teóricamente permite captar dependencias a largo plazo de manera más eficiente y acelerar el proceso de entrenamiento.
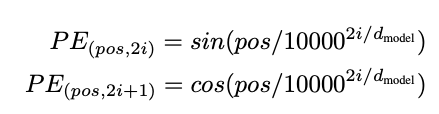
Auto-atención
El mecanismo de autoatención es lo que permite al modelo identificar con qué otra palabra de la secuencia está relacionada la palabra que se está procesando en ese momento.
Supongamos que queremos traducir la siguiente frase:
"Alice and Tom were playing soccer, but she scored the winning goal."
Cuando el modelo está procesando la secuencia, ¿a quién se refiere "she"?
Aunque esta puede parecer una pregunta sencilla para una persona, representa un problema complejo en el procesamiento del lenguaje natural (NLP).
El mecanismo de autoatención permite asociar "she" con Tom en vez de con el resto de las palabras.
Aunque las RNN (redes neuronales recurrentes) pueden referenciar palabras anteriores de la secuencia, sufren de problemas de memoria a corto plazo. Esto significa que, al trabajar con secuencias largas, las RNN tienen dificultades para referenciar palabras que aparecieron hace mucho tiempo.
El mecanismo de autoatención soluciona este problema, ya que, en teoría, tiene una ventana de referencia infinita, limitada solo por la potencia computacional. Esto permite que el algoritmo use el contexto completo para realizar la tarea.
En un Transformer, el texto fluye de manera simultánea entre el encoder y el decoder. Por lo tanto, es fundamental añadir información sobre la posición de cada palabra en el vector de secuencia. Los autores del paper decidieron aplicar una función sinusoidal para este propósito. No entraré en muchos detalles sobre esto, ya que se sale del alcance de este post.
Atención por producto escalar
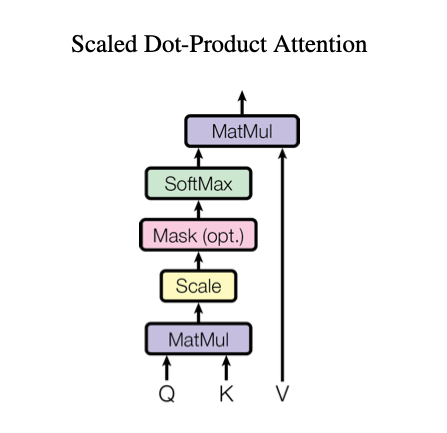
Para poder entender el mecanismo complejo de multi-cabezas
El mecanismo toma 3 valores de entrada:
- Q: se trata de la query que representa el vector de una palabra.
- K: las keys que son todas las demás palabras de la secuencia.
- V: el valor vectorial de la palabra que se procesa en dicho punto temporal.
Los valores V y Q son el mismo vector.El mecanismo nos devuelve la importancia de la palabra en el texto:
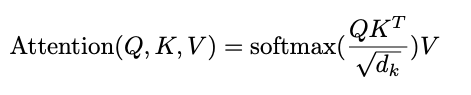
Realizar el producto escalar de Q y K (transpuesto) significa calcular la proyección ortogonal de Q en K. O sea, intentar estimar la alineación de los vectores y devolver un peso para cada palabra del texto.
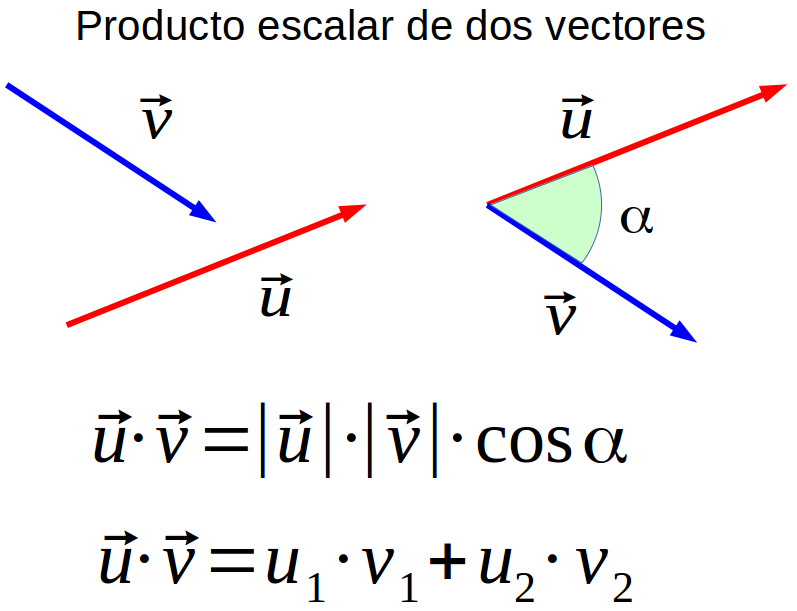
Se normaliza el resultado al dividir por la raíz del tamaño de K (o sea, por el tamaño de la secuencia). Esto se hace para evitar problemas de fuga de gradiente que se producirían en la Softmax si tenemos valores de gran tamaño. Aplicar la softmax se debe a intentar escalar el peso de la palabra en un rango entre 0 y 1. Finalmente, se multiplican estos pesos por el valor (el vector de la palabra con la que estamos trabajando) para reducir la importancia de palabras no relevantes y quedarnos solo con las que nos importan.
Auto-atención por multi-cabeza
La versión del mecanismo que utiliza un Transformer es una proyección de Q, K y V en h espacios lineales. Siendo h la cantidad de cabezas que tiene el mecanismo (siendo h=8 en el paper). Esto permite que cada cabeza se centre en aspectos diferentes, para después concatenar los resultados. El tener varios subespacios y, por lo tanto, varias representaciones de importancia de cada palabra. Esto permite que la propia palabra no sea la dominante en el contexto.
La arquitectura de multi-cabeza nos permite aprender dependencias mucho más complejas sin añadir tiempo de entrenamiento gracias a que la proyección lineal reduce el tamaño de cada vector.
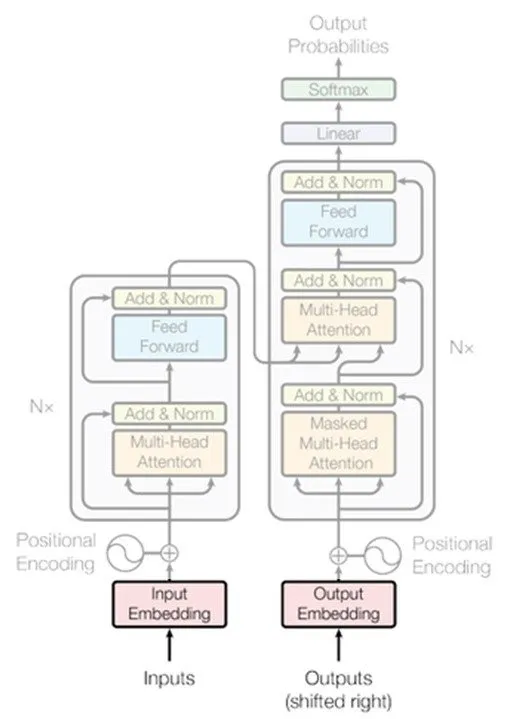
Arquitectura encoder-decoder
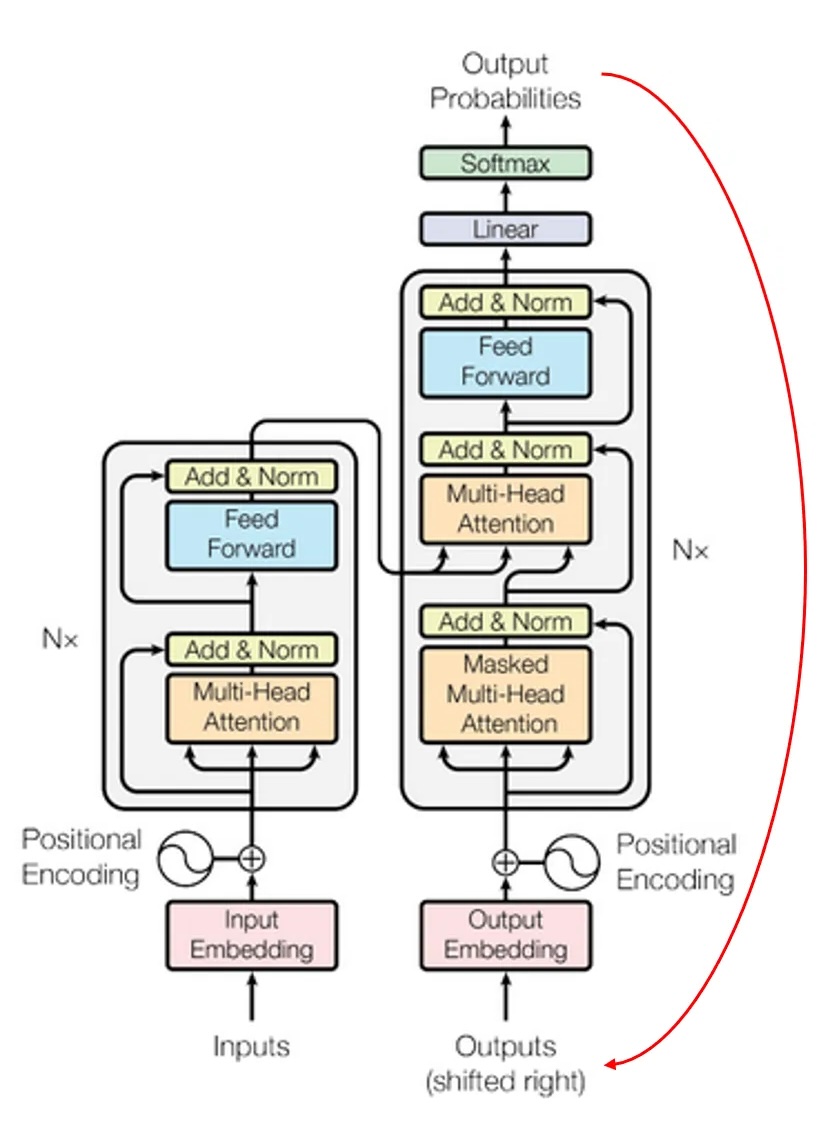
La Codificación
Se realiza un embedding de la secuencia de las palabras para convertir cada una en un vector y tener una representación numérica.
Añadir la componente
posicional para cada vector de palabra.
Aplicar el mecanismo de auto-atención de múltiples cabezas.
Capa neuronal Feed Forward.
La Decodificación
Se realiza un embedding del resultado del punto temporal justo anterior (t-1).
Se añade la componente posicional.
Se aplica el mecanismo de auto-atención de múltiples cabezas a la secuencia del output de t-1.
Se recoge la salida del encoder para el punto temporal t, aplicamos de nuevo el mecanismo de auto-atención, esta vez utilizando las palabras del output t-1 como V, y la salida del encoder (en t) como K y Q.
Capa neuronal de Feed Forward.
Capa lineal y una Softmax para obtener la probabilidad de la siguiente palabra y devolver aquella con la probabilidad más alta como la siguiente palabra.
Resultados
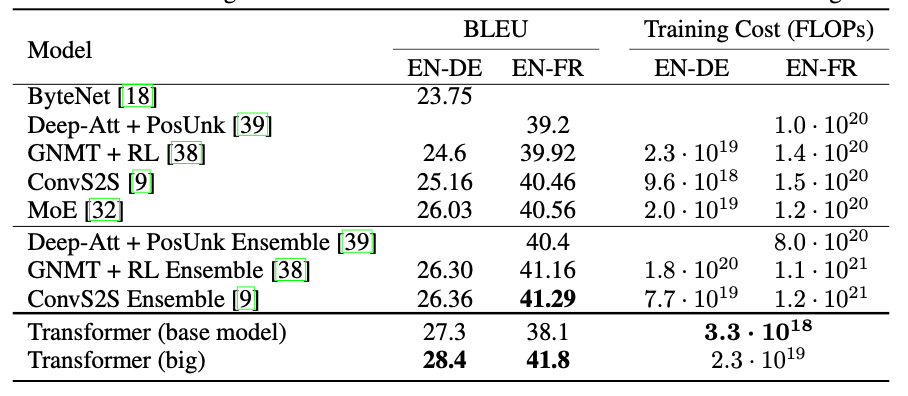
Este cuadro muestra que los modelos basados en transformers logran una buena combinación de alta calidad de traducción (BLEU alto) y un costo de entrenamiento relativamente bajo (menores FLOPs), especialmente comparado con modelos más antiguos o más complejos.
Conclusiones
La publicación del paper Attention is all you need de google, fue una revolución en el campo de NLP.
Los Transformers solventan los problemas de memoria que presentan las RNN
La clave de la arquitectura es el mecanismo de auto-atención y el uso de autoencoders para agilizar el entrenamiento y producir resultados top son la base del uso de GPT.
Los transformers son la base de los GPT y los grandes modelos de LLM y de los modelos de visión modernos